Artificial intelligence (AI) is revived these years because of the development of deep learning algorithms, which perform excellently in computer vision tasks (e.g. image recognition, detection) and nature language processing (e.g. machine translation, text generation). This is promising to revolutionize our society to enter an intelligent era. However, the fundamental computing hardware still face severe efficiency-issue when tackling these AI tasks, due to the limitations from the underlying von Neumann architecture. The frequent data shuffling between the separated computing and memory units accounts for large latency and power consumption in dealing with the data-intensive algorithms, which seriously limits the practical applications.
Memristor-enabled computation in memory (CIM) architecture is considered as a promising approach to substantially address the von Neumann bottleneck. Memristor is a kind of electrically synaptic device whose conductance could be easily modulated by applying appropriate voltages between the top and bottom electrodes. Organizing memristors in crossbar array and inputting the encoded voltage signals, the multiply-accumulate (MAC) computing, which is the key operation in deep neural networks, could be executed naturally in a physical manner (owing to basic Ohm’s law and Kirchhoff’s current law). Moreover, the massive MAC operations could be conducted in a parallel way within the memristor crossbars, where the calculating happens at the data-storage location. This emerging hardware with CIM architecture could strongly boost the computing efficiency in terms of the deep learning tasks and offer solid support for the wide AI scenarios from cloud to edge.

[ad_336]
Recently, Prof. Huaqiang Wu’s research team from Tsinghua University reported the up-to-date breakthrough regarding the CIM in Nature journal, titled as “Fully hardware-implemented memristor convolutional neural network” (authored by P. Yao et al). In this work, hybrid training and spatial parallel computing techniques are proposed and demonstrated in a fully hardware-implemented CIM system to efficiently realize a convolutional neural network (CNN). The CIM system could beat its counterparts by achieving an energy efficiency more than two orders of magnitude greater than that of graphics-processing units.
Professor Huaqiang Wu, the corresponding author of this paper, comments: “Memristor device is capable to be scaled down to 2nm size. With the help of 3D process, we could further realize an incredible device integrating density in a chip as the synapses in the brain. Nowadays, researchers tend to investigate the computation in memory system based on single-array macro and mostly focus on the fully-connected structure. However, in practical applications, we must have multiple arrays or cores to run a more complicated neural network, such as the convolutional neural networks. The challenges would be different in multiple-array system with the single array case, and the convolutional operations are still inefficient in this novel computation in memory system.”
In this research, a versatile memristor-based computing architecture was proposed for neural networks, and accordingly, eight 2K memristor crossbar arrays were integrated to implement the system. Especially, the team optimized the device stacks and developed a fabricating process which is compatible with current foundry process. The fabricated memristor arrays exhibit uniform multilevel resistive switching under identical programming conditions.

Mr. Peng Yao, the first author of this paper, comments: “When deploying a complete CNN into the multiple memristor arrays, the system performance would degrade due to the inherent device non-ideal characteristics within and between arrays. Conventional ex-situ training method could not address this problem with acceptable cost, and tuning all memristor weights by in-situ training method is hindered by the device nonlinearity and asymmetry and sophisticated peripheral modules.”
[rand_post]
The non-ideal device characteristics are considered as the substantial hurdles to result in the system performance degradation. To circumvent various non-ideal factors, a hybrid training method is proposed to implement the memristor-based CNN (mCNN). In the hybrid training, the ex-situ trained weights are firstly transferred to the memristor arrays, and in the next phase, only a part of the memristor weights are in-situ trained to recovery the system accuracy loss due to device non-ideal characteristics. In this paper, only the last FC layer is in-situ trained to reduce the hardware expense.
Meanwhile, in mCNN, the memristor-based convolutional operations are time-consuming due to the need to feed different patches of input during the sliding process. In this manner, the team proposed a spatial parallel technique by replicating the same kernels to different groups of memristor arrays. Different memristor arrays could deal with different input data in a parallel way and expedite convolutional sliding tremendously. The device non-ideal characteristics could incur the random transferring errors in different memristor groups regarding the same kernels, therefore, hybrid training method is adopted at the same time.
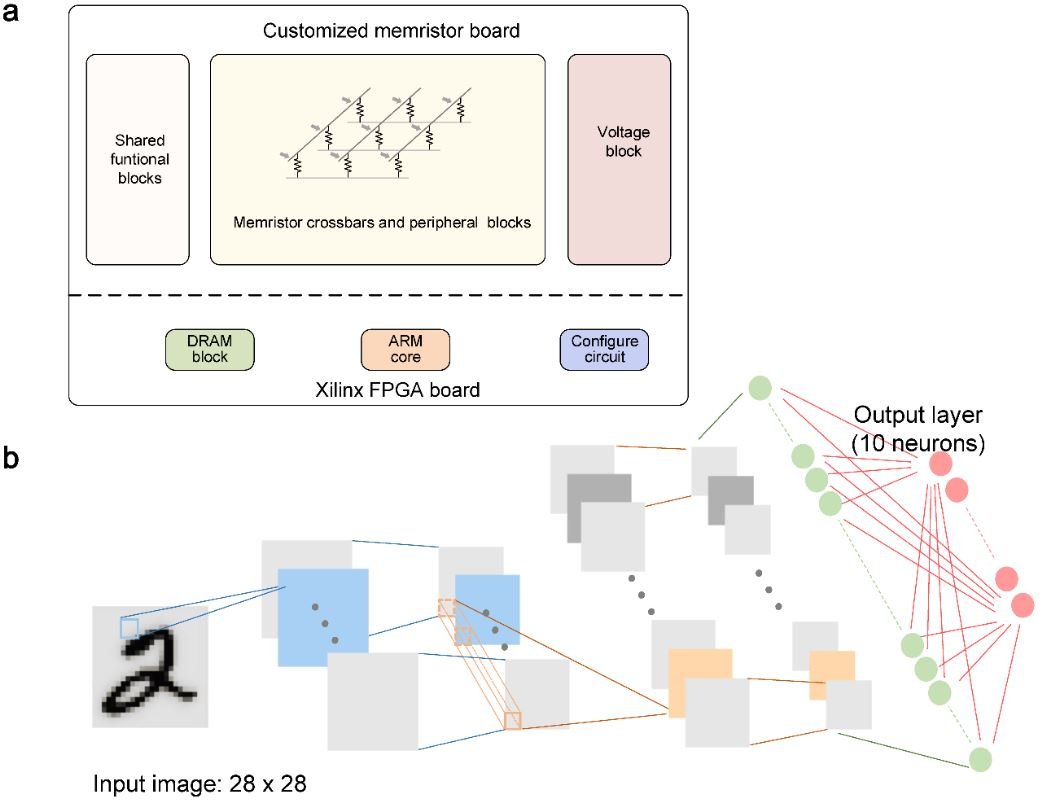
The methods and experiments in the multiple memristor-array system are momentous for both fundamental studies and diverse applications. It suggests that for CIM system, the device non-ideal characteristics at the bottom level could be effectively addressed by the strategies at the system level. The proposed hybrid training method and spatial parallel technique at system-level have shown to be scalable to larger networks like ResNET, and they could be extrapolated to more general memristor-based CIM systems.
Professor Huaqiang Wu is positive and enthusiastic: “The hybrid-training method is a generic system-level solution that accommodates non-ideal device characteristics across different memristor crossbars for various neural networks, regardless of the type of memristive devices. Similarly, the spatial parallel technique could be generally extended to other computation in memory systems to efficiently enhance their overall performance. We expect that the proposed approach will enable the development of more powerful memristor-based neuromorphic systems, and finally revolutionize artificial-intelligence hardware”.